Real World, Blind Evals
Finding AI models that work for real estate law

December 18, 2025

We’re hiring! Explore our Product Engineering Guide to learn how we build at Orbital.
How We Evaluate New LLMs at Orbital
Every few months, one of the AI labs drops a new model. Increasingly, competing labs drop new models within weeks of one another.
Benchmarks light up, feeds fill with leaderboards, and legal tech vendors rush to announce they’ve “integrated the latest frontier model”.
At Orbital, those days look a little different for us.
Yes, there’s excitement (and sometimes a launch party, with pizza!). But between a new model announcement and that model touching a live real estate transaction via our products, there’s a lot of quiet, deliberate work.
This post is a look behind the curtain at how we evaluate new LLMs at Orbital, and decide which ones are actually good enough to make it into our product, which customers use to fast-track Real Estate legal work.
Benchmarks are where we start, not where we end
Public benchmarks are useful but limited. Improvements tend to correlate with better reasoning, but they don’t always translate to real-world performance. Most benchmarks test short, self-contained tasks rather than complex, multi-step, real estate specific workflows that Orbital Copilot is expert in. A model that tops a coding leaderboard won’t automatically understand the intricacies of a 120-page commercial lease.
Our products live in a very specific world: real estate law and practice, idiosyncratic drafting (sometimes decades old), and high-stakes decisions about risk, enforceability and deal viability.
So, we treat headline scores as orientation, not evidence.
Our real questions are always, among others:
- Is this model, when paired with all of the architecture and proprietary knowledge we’ve built, better at identifying key clauses and risks?
- Is it better at understanding how they interact in a particular jurisdiction and deal structure?
- Does the new model explain its reasoning in a way a property lawyer would trust?
To answer that, we go beyond generic benchmarks and run our own.
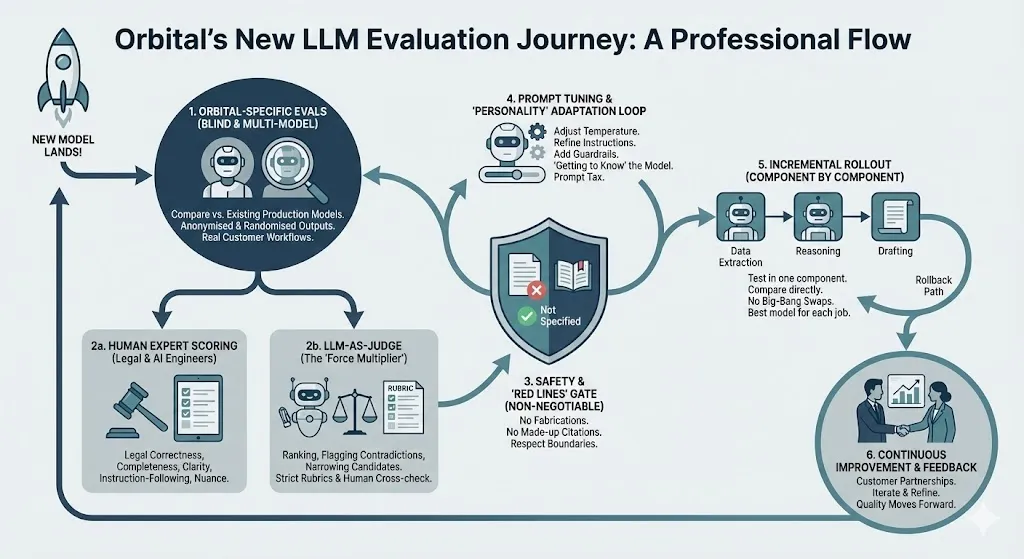
Real-world, blind evals
When a new model lands, we run it through a suite of Orbital-specific evaluations built from real customer workflows across global real estate transactions.
We always compare against our existing production models on the same tasks. “Better” only matters if it’s better for real work.
To reduce bias, we evaluate blind wherever possible. Outputs from multiple models are anonymised and randomised. Legal Engineers, AI Engineers and others score them on (specifically in the context of real estate legal workflows): legal correctness, completeness, clarity and usefulness, instruction-following, and requisite level of detail and attention to nuance.
We also use LLM-as-judge setups as a second lens, where AI models score outputs against the same criteria.
Different jobs, different models – and no big-bang swaps
Orbital doesn’t run on a single mega model. We use different models in different parts of our system, with the best models for each aspect chosen. For example, one model may shine at raw data extraction but be less reliable at reasoning, or vice versa.
We don’t replace everything at once. Instead we:
- Test a new model in one component at a time
- Compare it directly to the existing model in that role
- Roll out changes incrementally, always with a rollback path
That keeps quality moving in the right direction without nasty surprises for customers.
Models have personalities (and prompts matter)
One thing we’ve learned: models have personalities.
Some are cautious and hedged, others (over-)confident and concise; some are verbose, others hyper-literal.
Our first evals usually reuse prompts tuned for our existing stack – that’s how we get a fair baseline. But those initial results are rarely the whole story.
The second phase is “getting to know” the model: adjusting temperature and other parameters, refining instructions according to demonstrated model behaviour and published characteristics, and adding guardrails.
Plenty of models go from “underwhelming” to “clear upgrade” once we adapt prompts and configuration for our specific use cases. The topic of “prompt tax” is something our CTO, Andrew Thompson, has spoken about previously.
We’re not just comparing raw intelligence; we’re comparing how well we can work with a model.
Using LLMs to evaluate LLMs (carefully)
We use LLMs-as-judges to help scale evaluation: ranking outputs on clarity, consistency and faithfulness to the source text, flagging contradictions or invented details, and narrowing down candidates before deeper human review.
We design strict rubrics and still cross-check with humans. LLMs-as-judges are a force multiplier, not a final authority – especially in legal.
Safety, trust and “red lines”
Because our outputs inform real estate legal advice and investment decisions, we maintain non-negotiable red line tests:
- No fabricated clauses
- No made-up citations
- No confidence guessing where the document is silent
We would rather have “Not specified” than a polished hallucination.
Only models that respect those boundaries progress through our evaluation process. That said, as a team that has worked with LLMs since they first became available to developers (back to the GPT-3.5 days), we understand that their non-deterministic nature means some undesirable behaviour will still surface in the wild. When it does, we draw on our strong partnerships with customers to further iterate and refine the model implementation.
Launch watch parties: the fun bit
When a hotly anticipated new model is launched, promising big jumps in performance, a cross-functional group of AI enthusiasts from across Orbital – Legal Engineering, AI Engineering, Product and beyond – will often pile into a room (or a call) to watch the lab’s launch event: live streams, demo videos, model cards, early examples. A chance to geek-out!
The last one clashed with the start of our all-company social, but we still got a decent turnout!
We share first reactions in real time:
“That tool use demo is interesting, but how would it cope with a 200-page lease?”
“The reasoning examples look strong – we should test it on break clauses and alienation next.”
Our “launch watch” channel fills with clips, notes and questions to probe once we get API access. Only after that shared debrief do we bring the model into our own evaluation harness and test it against real Orbital workflows.
It’s a mix of curiosity and discipline – a reminder that while we’re genuinely excited by what’s possible, the real work starts when we see how a new model performs on the messy, high-stakes reality of real estate law.
Final thoughts: depth over hype
For us, as a business hyper-focussed on how models perform in legal for real estate, it’s not about a knee-jerk implementation of a new model based on public hype.
It’s: “Will this new model, implemented in the right parts of our system, improve its ability to handle real estate legal workflows?”
At Orbital, that proof comes from: domain-specific evals built for real estate law, blind testing and multiple perspectives across Legal and AI Engineering, incremental safe rollouts rather than risky big-bang changes, and a willingness to adapt to each model’s “personality” to get the best from it.
New models will keep arriving, with ever higher leaderboard scores. Our job – and our promise to our customers – is to keep doing the unglamorous work of testing, probing and validating, so that when a new model does reach your workflow, it’s there because it’s genuinely better for the deals you’re trying to get done.
Did you know…
At Orbital, we have tested tens of models from many different providers over the years! Here’s a flavour of the models we have put through their paces:
| Provider | Model Name | Evaluation Status |
|---|---|---|
| Anthropic | claude-opus-4 | Formally Evaluated |
| Anthropic | claude-opus-4-20250514 | Formally Evaluated |
| Anthropic | claude-sonnet-4 | Formally Evaluated |
| Anthropic | claude-sonnet-4-20250514 | Formally Evaluated |
Gemini 3 pro | Experimented with | |
Gemini-2.5-flash | Experimented with | |
Gemini-2.5-pro | Experimented with | |
| Nanobanana | nanobanana | Experimented with |
| Nanobanana | nanobanana pro | Experimented with |
| OpenAI | ft:gpt-3.5-turbo-0125:orbital-witness::9PXrPxvp | Fine-tuned |
| OpenAI | ft:gpt-3.5-turbo-0613:orbital-witness::8kbLospm | Fine-tuned |
| OpenAI | ft:gpt-3.5-turbo-1106:orbital-witness::8TC0l6bi | Fine-tuned |
| OpenAI | ft:gpt-3.5-turbo-1106:orbital-witness::8q0ohpqn | Fine-tuned |
| OpenAI | gpt-4.1-nano | Fine-tuned |
| OpenAI | gpt-4.1-nano-2025-04-14 | Fine-tuned |
| OpenAI | gpt-3.5-turbo | Formally Evaluated |
| OpenAI | gpt-3.5-turbo-1106 | Formally Evaluated |
| OpenAI | gpt-4 | Formally Evaluated |
| OpenAI | gpt-4-0125-preview | Formally Evaluated |
| OpenAI | gpt-4-0613 | Formally Evaluated |
| OpenAI | gpt-4-1106-preview | Formally Evaluated |
| OpenAI | gpt-4-32k-0613 | Formally Evaluated |
| OpenAI | gpt-4-turbo-2024-04-09 | Formally Evaluated |
| OpenAI | gpt-4.1 | Formally Evaluated |
| OpenAI | gpt-4.1-2025-04-14 | Formally Evaluated |
| OpenAI | gpt-4.1-mini | Formally Evaluated |
| OpenAI | gpt-4.1-mini-2025-04-14 | Formally Evaluated |
| OpenAI | gpt-4o | Formally Evaluated |
| OpenAI | gpt-4o-2024-05-13 | Formally Evaluated |
| OpenAI | gpt-4o-2024-08-06 | Formally Evaluated |
| OpenAI | gpt-4o-2024-11-20 | Formally Evaluated |
| OpenAI | gpt-4o-mini | Formally Evaluated |
| OpenAI | gpt-4o-mini-2024-07-18 | Formally Evaluated |
| OpenAI | gpt-5 | Formally Evaluated |
| OpenAI | gpt-5-2025-08-07 | Formally Evaluated |
| OpenAI | gpt-5-mini | Formally Evaluated |
| OpenAI | gpt-5-mini-2025-08-07 | Formally Evaluated |
| OpenAI | gpt-5-nano | Formally Evaluated |
| OpenAI | gpt-5-nano-2025-08-07 | Formally Evaluated |
| OpenAI | o1-2024-12-17 | Formally Evaluated |
| OpenAI | o1-mini-2024-09-12 | Formally Evaluated |
| OpenAI | o1-preview-2024-09-12 | Formally Evaluated |
| OpenAI | o3 | Formally Evaluated |
| OpenAI | o3-2025-04-16 | Formally Evaluated |
| OpenAI | o3-mini-2025-01-31 | Formally Evaluated |
| OpenAI | o4-mini | Formally Evaluated |
| OpenAI | o4-mini-2025-04-16 | Formally Evaluated |
We’re hiring
If you are interested in helping us solve some very hard problems building the world’s first AI-powered real estate lawyer, see our open roles and get in touch with us via our Careers Page. If nothing quite matches your experience please connect with and message me directly on LinkedIn, Andrew Thompson, and I’d be happy to have a chat with you.
Ben Sainsbury & Gus Levinson
Legal & AI Engineering
