3 day hackathon with large language models (LLMs)
Six of our talented engineering teams hacked around with GPT-4

May 23, 2023
We’re hiring! Explore our Product Engineering Guide to learn how we build at Orbital.
Update (January 2026): This post reflects our approach at the time of writing and our tech stack has since evolved. Treat as historical context.
Background
On May 3rd, 2023 the engineering and data science department at Orbital had a 3 day hackathon centered around large language models (LLMs) such as OpenAI’s GPT-4. We decided to give this hackathon a focused theme around LLMs given how much has happened in the last 6 months since OpenAI released ChatGPT. Here is the theme that we described to everyone:
ChatGPT took the world by storm on November 30, 2022 and over the last few months we’ve seen a flurry of releases included GPT4, GPT Plugins, Bing AI, Google Bard and many other open-source Large Language Models (LLMs) coming to market which are being used in B2C and B2B products. This technology is incredibly impressive in its capabilities and is being hailed as the next platform shift in computing analogous to the introduction of the internet, mobile and cloud computing.
Orbital’s mission as a company is to automate property diligence for anyone. For the last few years, prior to ChatGPT’s launch, we’ve been building NLP-based products for commercial and residential law firms. Given that we’ve already been developing machine learning systems in the NLP space, we wanted everyone across the business to not only be aware of this new LLM technology but also to be very knowledgeable about what it can do, what it can’t do and how we use it to build product that solves our customer’s specific problems in new and innovative ways. We’re now able to build product features, using LLMs, that simply weren’t considered possible last year and it was worth everyone across the business appreciating this change.
This purpose of this hackathon is (a) to have fun and collaboratively work with colleagues, (b) get a deeper understanding of generative AI concepts, LLMs in general and more specifically OpenAI’s ChatGPT and GPT4 functionality, and (c) hack together an impressive product feature, using an LLM, that is applicable to Orbital’s mission and then demo it company-wide.
Structure
Prior to the actual start date of the hackathon we wanted to keep things unstructured to let creativity reign but we also wanted to add in a bit of organisation so everyone was prepared:
- Our Head of Data Science, Matt Westcott, initially gave an internal presentation about building with LLMs given his team’s recent experience experimenting with them. His team has also created a bunch of internal tools that people could leverage if they wanted.
- We randomly selected which colleagues would work together on each team about two weeks before the hackathon (we had six teams with two people on each team)
- We created a Slack channel to share countless ideas of what other companies are doing along with tips and tricks of how to write better prompts, how to think about effective build retrieval systems and how to use OpenAI’s various models effectively.
- We booked out a room in Shoreditch for the team to meetup for breakfast, begin hacking together, have time for a communal lunch and finally have drinks afterwards to decompress


Hackathon Show & Tell
Below I’ve highlighted the hackathon idea of what each team worked on and included both a basic architecture diagram and a short video clip of what they ended up building.
Team 1
Hackathon Idea: Effortlessly navigate available data with advanced search, filter, sort and grouping
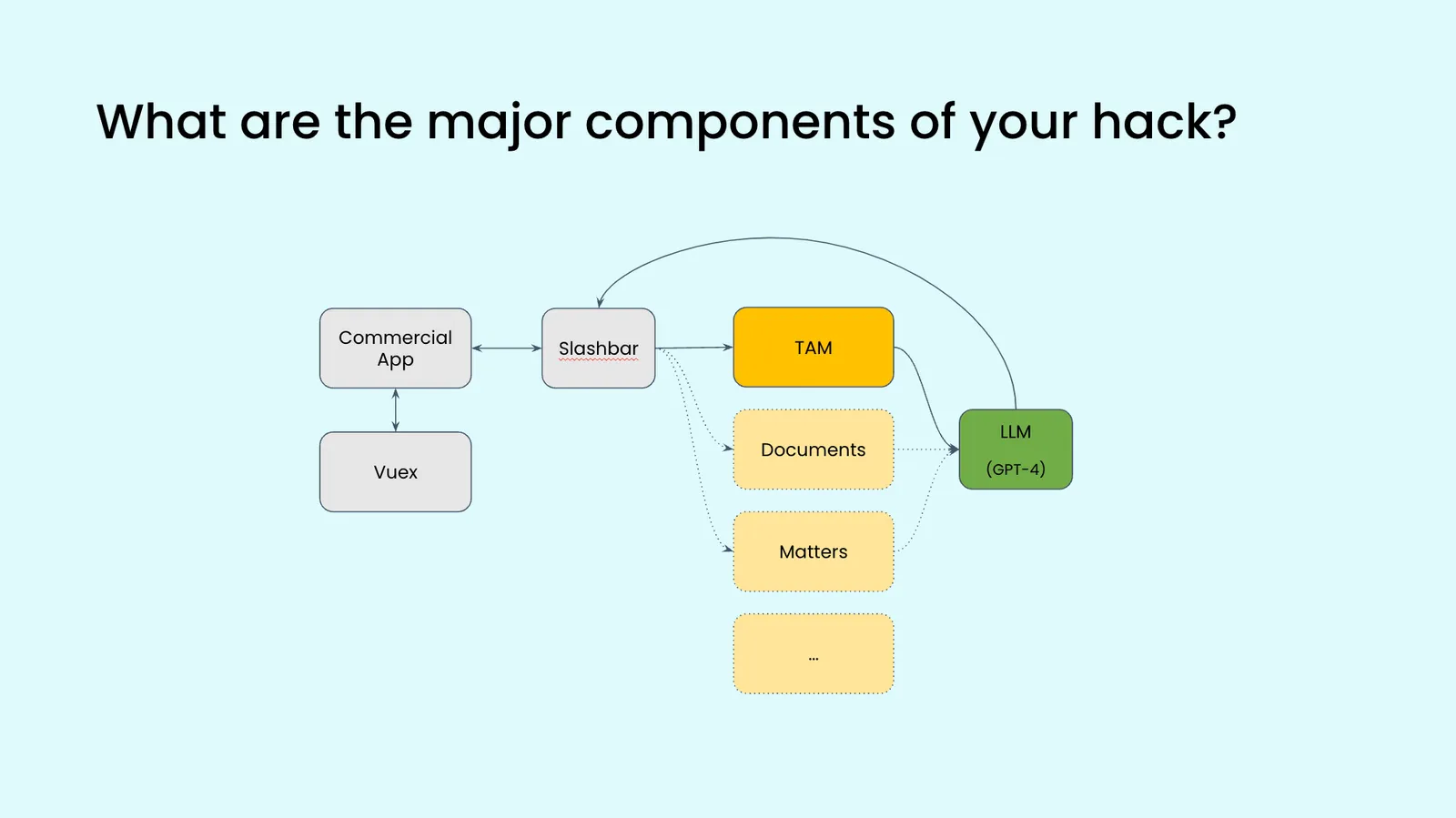
Team 2
Hackathon Idea: Generate any kind of custom report clients can throw our way
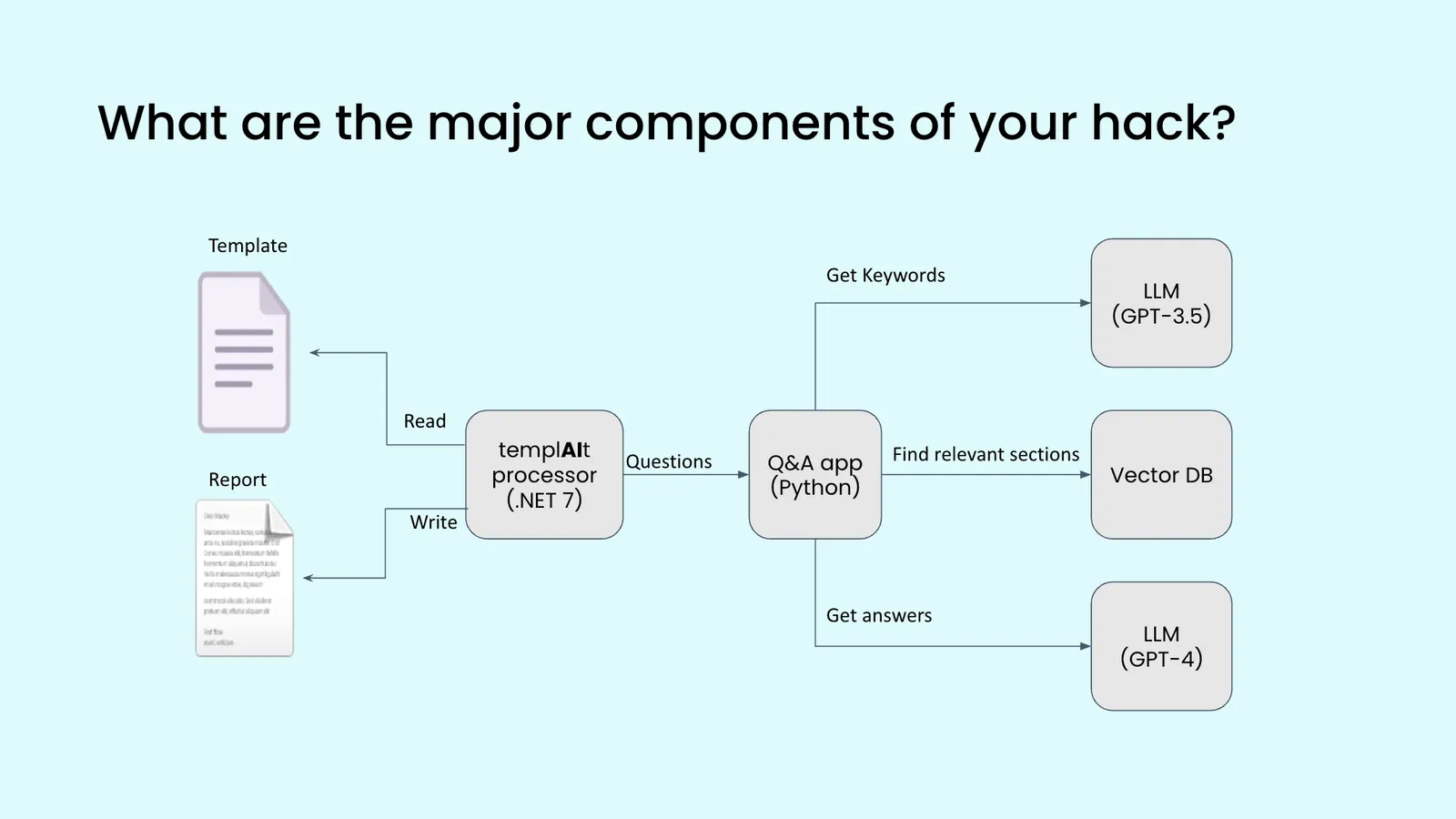
Team 3
Hackathon Idea: Automatic Walkthroughs (…or how LLMs can automate all of the Commercial App)
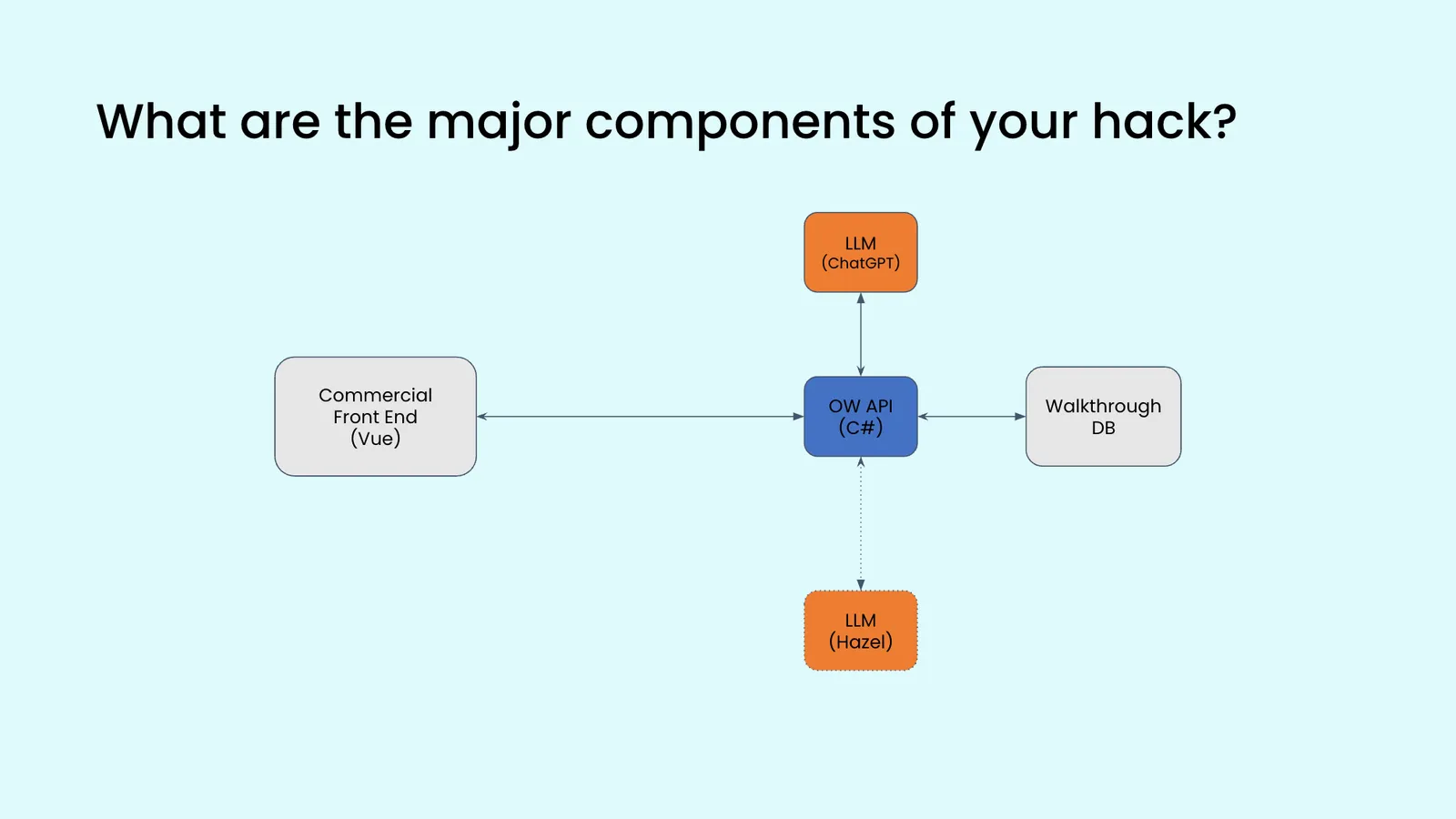
Team 4
Hackathon Idea: Automate Benefits versus Burdens
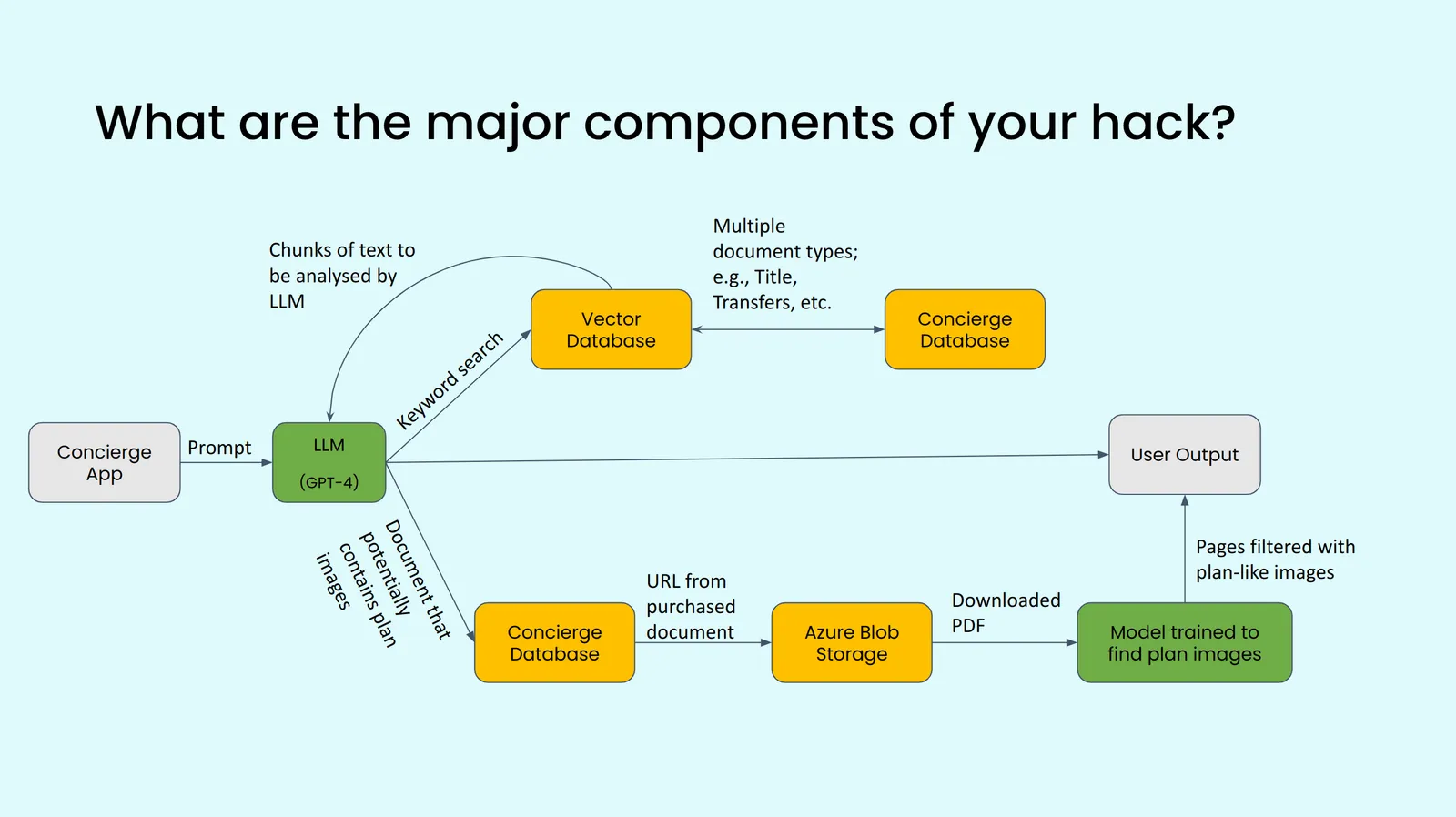
Team 5
Hackathon Idea: Show crime data within the proximity of a title
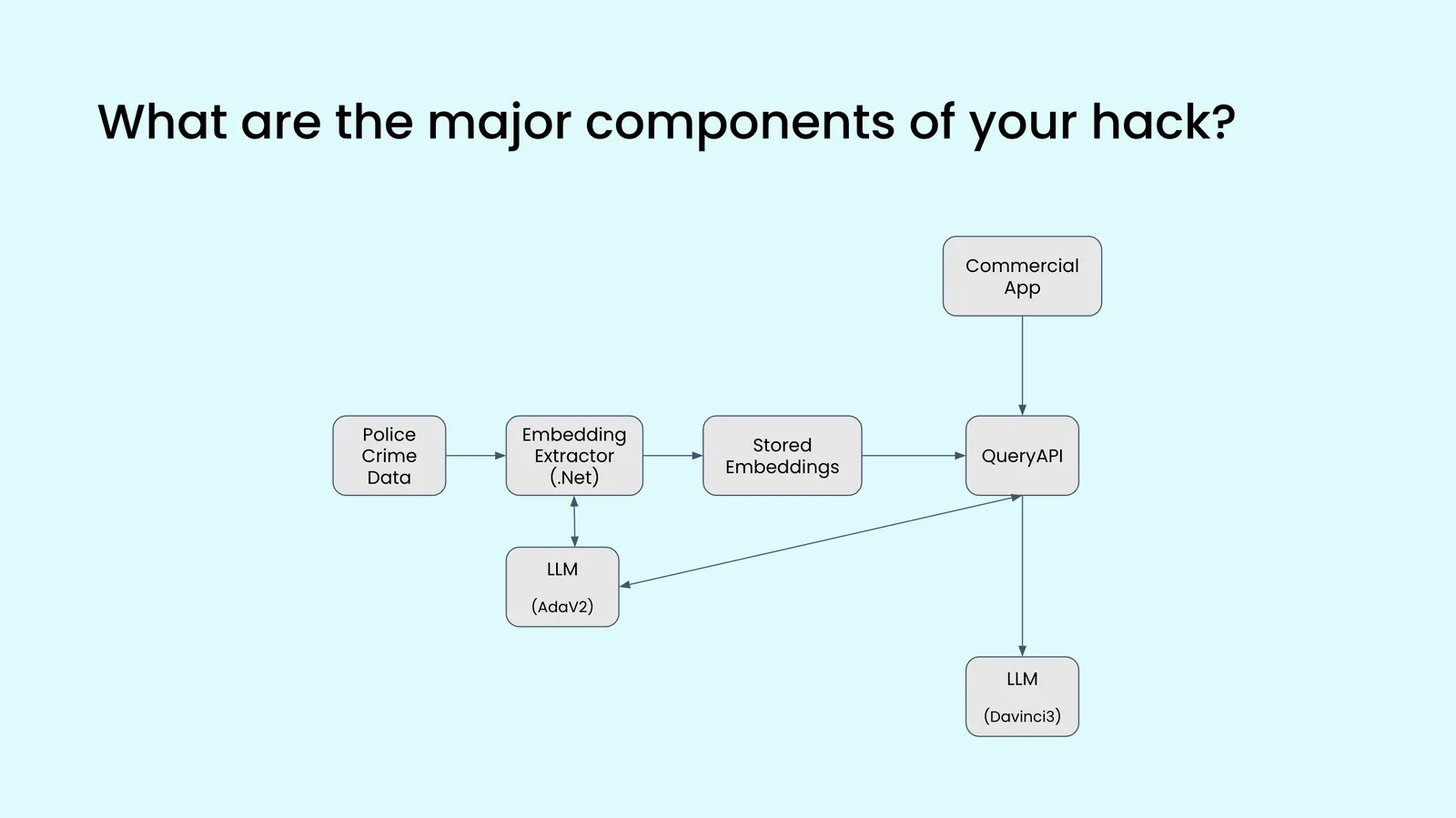
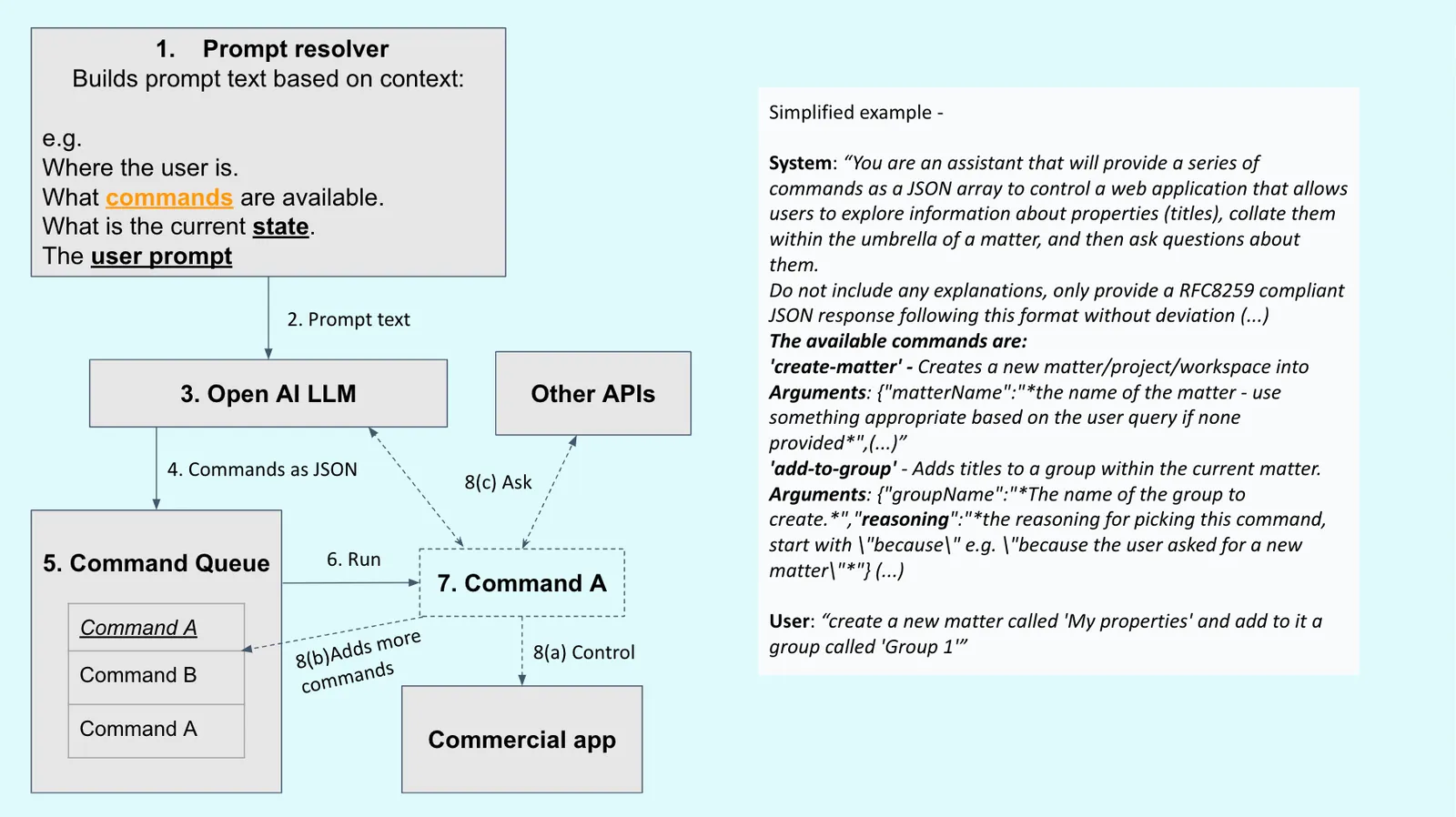
Team 6
Hackathon Idea: An assistant built into the Commercial App that captures user intent and actions it

Cost
Although much has been written online about how expensive GPT-4 is, experimenting with it during the hackathon was rather cheap across all of our teams for the 3 days.
If this was a traditional machine learning project teams would have found it far more expensive to get up and running both in terms of time and money. Collecting and then training a model on a large set of labelled data is a time consuming and expensive process. However using this new LLM paradigm (where zero-shot / few-shot prompts are the norm and fine-tuning models isn’t initially required) has actually flipped the costing of projects where experimentation is actually now far cheaper than it was previously and production inference is where the costs really start to stack up quickly.
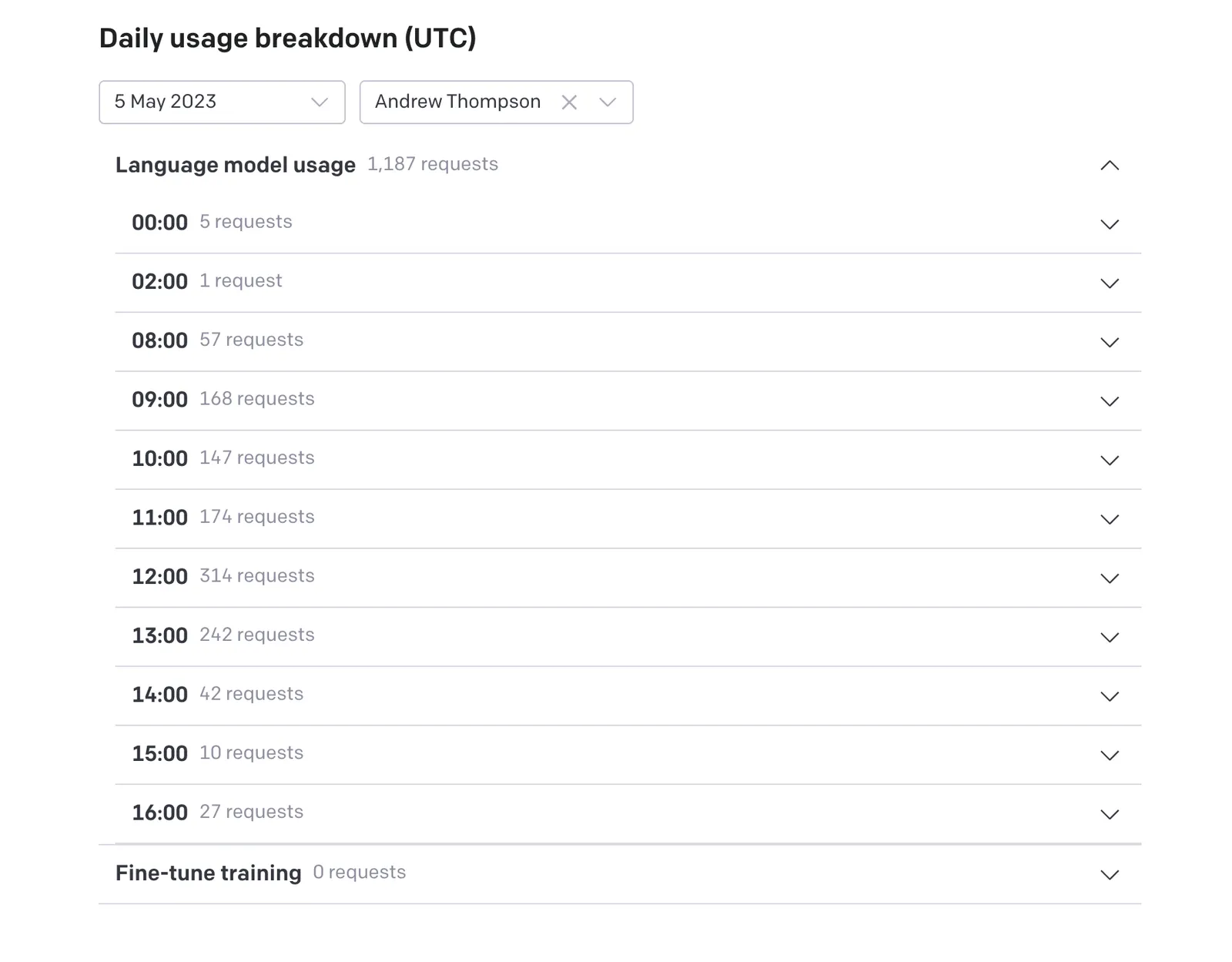
Across all teams during the entire hackathon we only spent a paltry total of $94.30 on all OpenAI usage. Each team had a budget of $500 and clearly they got nowhere close to consuming it. Here is our actual usage of OpenAI’s GPT-3.5/4 on each day of the hackathon:
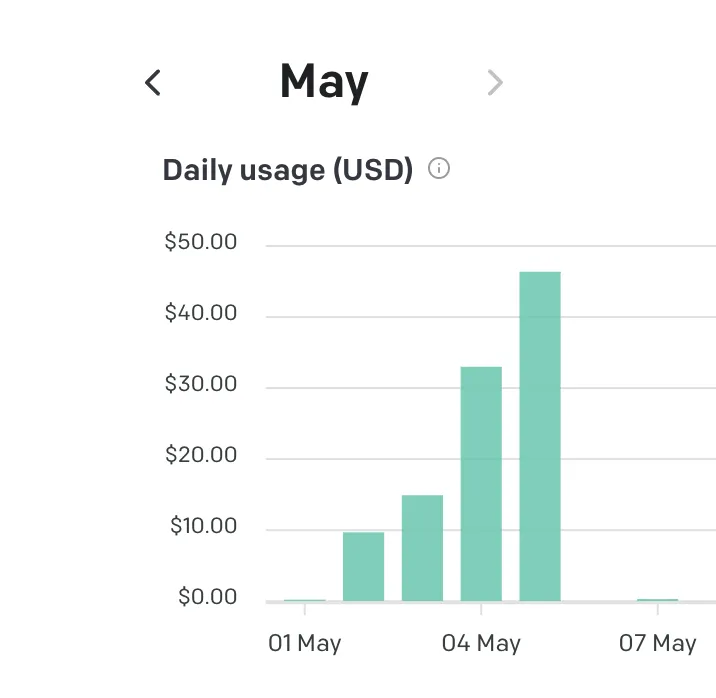
Here’s a breakdown of the number of API calls on the final day of the hackathon across all teams:
We’re hiring
If you are interested to know more about how we work and what our next hackathons might be please see our open roles and get in touch with us via our Careers Page.
Andrew Thompson
CTO


