The journey to continuous deployment
Let the robots do the hard work!

March 29, 2022

We’re hiring! Explore our Product Engineering Guide to learn how we build at Orbital.
Update (January 2026): This post reflects our approach at the time of writing and our tech stack has since evolved. Treat as historical context.
The journey to continuous deployment
Let the robots do the hard work!
This is the journey we took to move the frontend VueJS application from a once a week release cadence to multiple daily deployments.
Boarding passes please
When I joined Orbital in 2020 the UI was a VueJS application embedded in a .NET MVC project that all formed one big monorepo. The .NET MVC project provided the APIs to send/receive data within the VueJS application. The project had to be deployed as a whole; fix a spelling mistake in the VueJS application and the whole project had to be deployed, APIs and all.
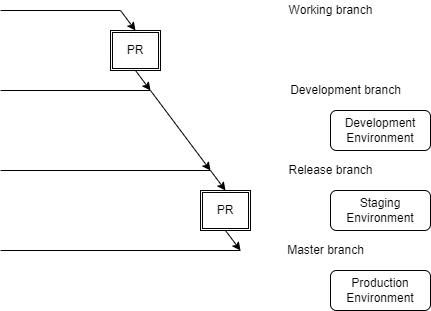
The release process had some automation but all the triggers were manual. These were the steps involved with the pull request (PR):
- Create a PR from the working branch into the development branch
- Unit tests and a build were performed on the PR branch
- Merge the PR which automatically triggers a deployment into the development environment
- Manually create a release branch with a specific name
- Creating this branch automatically triggers a deployment into the staging environment
- Raise a PR to merge the release branch into master
- Unit tests and a build were performed on the PR branch
- Merge the release PR which automatically triggers a deployment into the production environment
As a team we agreed that the VueJS application needed to be separated from its API project so that both could be released independently. This allowed frontend changes to ship far quicker and more iteratively.
The first port of call
The first problem we addressed was the lack of automated testing. Every release required manual testing on the staging environment as well as confirmation testing when released to production. A spreadsheet of core journeys was developed and followed for each release. Because of this, each release took 1-2 days to move from development to production. This involved multiple members of the team and we were all losing development time each week to manage and test the release.
There were a limited number of unit tests using the standard vue-test-utils package. These did not cover all components and were not sufficient to give us confidence in a release.
We decided to increase the unit tests within the application so that every new component now included one. When returning to older components, refactoring was usually required, but we managed to start adding tests to these too.
Once unit testing had been addressed and our test suite started growing nicely, our next step was to start adding end-to-end testing. We decided to use Cypress to write our tests because the team was familiar with the product. There is also a large community around Cypress testing and great documentation so there are a lot of resources available when needed.
There was a concerted effort from the whole team to build out the core journeys and get them running in each environment as part of the release builds. We had developed a spreadsheet of test journeys from the manual testing, so these are the journeys we created Cypress tests for. After around a month we had replaced the need for the spreadsheet and the manual testing for each release. This meant we were able to release 2-3 times per week! This was not only a great morale booster for the team but increasing deployment frequency is mentioned as one of the four key metrics by Nicole Forsgren, Jez Humble and Gene Kim in their popular evidence based Accelerate book.
Trouble at the border
Any client-side application talking to an API needs to deal with security, unless the data is going to be available to the public. As the VueJS application was embedded in a .NET application it was leveraging the free security that comes with that technology, namely setting cookies during the login process. This works as everything is hosted on the same domain and the .NET framework takes care of everything. However, to get the VueJS application to deploy separately, the application and the API would need to be deployed on separate domains meaning the existing cookie authentication would no longer work.
We decided that JSON Web Tokens (JWT) needed to be introduced with a separate Identity Server that can deal with authenticating both users in the VueJS application and the APIs on the servers. There is already plenty written online about JWT and Identity Server, so I won’t go into the details here. Suffice to say, it took a lot of effort to get the application to work with the Identity Server. Then again, security is not something you want to rush! By the end of this process we had a VueJS application that was no longer reliant on the .NET Core project and we could finally look to separate the two projects.
It’s worth noting that by re-using the user database within Identity Server there was no user appreciable difference in the application except a re-designed login screen. This work also didn’t directly change the release cadence from the 2-3 days per week we had already achieved.
Entry to (techie) paradise
The final step was to move the VueJS code out of the monorepo and host it separately from the APIs. After researching a number of hosting methods we chose Azure Static Web Apps (ASWAs). These were introduced in May 2021, which was around the time that we were investigating hosting solutions. Our main reasons for choosing Azure Static Web Apps were our desire for:
- A hosted solution
- Simple to deploy code from a build tool
- A great developer experience
- Plus, it gave us PR environments for free
We used Microsoft DevOps to host our codebase and also to run deployment pipelines to release the code. ASWAs were supposed to work with the existing pipelines, but it soon became apparent that support was limited and most documentation was around Github Actions. We took the decision to move the VueJS application code into Github and use Github Actions to deploy the code. This is something the team had been talking about, so we viewed it as a good way to learn about hosting and deploying code from Github. With a lot of reading, trial and error we created a fully automated release process:
- The developer raises a PR for review
- Due to ASWAs creating dynamic environments for a PR, we are able to let the wider business see and approve the changes before they are merged into the codebase
- The PR is reviewed and merged which triggers a deployment to our development environment
- Unit tests, code quality tools and the end-to-end tests are all run as part of this build and deployment process
- On a successful deployment to the development environment a PR is automatically opened to merge the code into the production branch
- This gives us another dynamic environment to build, test and deploy to. The environment is actually set up to point to production APIs and allows us to test as though it was a full production environment
- Finally, the PR is automatically merged into the production branch which triggers the final build test and deployment to production
There were a few teething troubles mainly because the .NET project had been injecting some values directly into the HTML page that hosted the VueJS application. These values were soon moved and imported in other ways and we had the VueJS application and the APIs running on separate domains and still working (after some CORS jiggery-pokery that was SO much harder than it should be!).
While moving the codebase from DevOps to Github and getting the VueJS application working in ASWAs, we were still developing and releasing updates and new functionality in the old codebase. We had a final merge of the code, switched the DNS and had our desired outcome. With the VueJS application now totally separated from the APIs we are able to release code multiple times a day without any developer being involved (after the code review of the initial PR). The whole process from merging the initial PR to the code being in the production environment takes around 1.5 hours.
Lessons learned
- Patience is a virtue! This whole process took the best part of a year to achieve in stops and starts. Once we had planned the whole journey, we split it into incremental steps that were then prioritised with the ongoing product features and enhancements that had to be delivered at the same time.
- Adopting new tech early can have its own problems. The ASWAs were very new when we started using them and there was a lack of documentation and community support on the web. This meant that getting past the basics in the tutorial was a challenge at times.
- End-to-end testing is an investment. Not only do you invest in creating the test suite, but it also needs maintenance and ongoing work. As the results of the work are not always visible and apparent to the wider business there is some knowledge sharing to understand the importance of the tests in a fully automated deployment pipeline. The investment has paid off a number of times by stopping bugs being released into production.
- I haven’t mentioned it above, but we implemented feature flags using LaunchDarkly. It quickly became apparent that continuously releasing code meant partially completed work ends up in production and we need to restrict access to it. This has meant that we are able to separate deployment of features and the releasing of features. The product team are now able to release features to users when they are ready.
Steve Doggett
Engineer

